I’m doing a cloud migration to a SharePoint library, it’s for a law office so they have tons of documents, pictures, video, audio, and many many folders. After addressing the various oddities with Migration Manager…
Ok, a quick tangent, if you have a path C:\Shares\General and the share is “General” and you want to migration this to a SharePoint Library\Folder it seems logical to simply import C:\Shares\General as the source path. This is wrong, you have to go up one level because otherwise every 1st level folder is added as an independent source in the migration manager (this folder had over 1000). This means any errors have to pull a log from Azure for each folder, there is no way to automate that process and there is a delay on pulling that file from Azure (it seems to build it on the fly). Once I figured out that I needed to point it to C:\Shares, I then just selected General and we’re good to go, it also scanned faster but that could be because it had the results cached from my previous run through with every individual folder as it’s own source, that process took almost a solid business day to complete, once I got the path right, it was about 4 minutes.
So now instead of pulling tons of tiny logs individually and also adding them to the migration job one by one (this was when I knew I had something wrong), we get one log detailing the results of each file in it.
This log was 388MB, 1,173,215 lines.
Excel would not fully open it, it would concat it.

Notepad++ would open it but it took a few seconds. So I thought, no big deal, splitting a file shouldn’t be hard…
In hindsight I think I should not have included CSV in my query, moving the header to the relevant output files would be a trivial manual task and processing the file as a CSV was not necessary but my google searches and later ChatGPT, made valiant attempts at doing the split for me. The problem is, even with optimization powershell is really slow handling large datasets.
I abandoned that path, let’s re-think this, what’s in the CSV that I want? Errors. What’s in the CSV, fucking everything, every single file even if it has no problems at all.

Another regex post? I’m really looking like that regex guy that just tells everyone how great regex is.
It is though.
In Excel I could use my concat file to see that generally there are only 3 errors in this file:
INVALID_SHAREPOINT_NAME
PATH_LEN_GT_300
ITEM_IS_EMPTY
With the item is empty, I checked a few files and it’s right, I’m not sure why they’re empty but SharePoint can’t do anything with a 0 byte file, so those won’t migrate, that’s fine, I don’t really care about those. So that leaves path length which does need addressing manually (I sometime use zipping the folder structure somewhere along the path if the customer doesn’t want to lose the contents as they are) and invalid SharePoint name which is typically just the temporary word document files (starting with ~$)
First I set NPP to Regex and set it to mark with Bookmark selected:

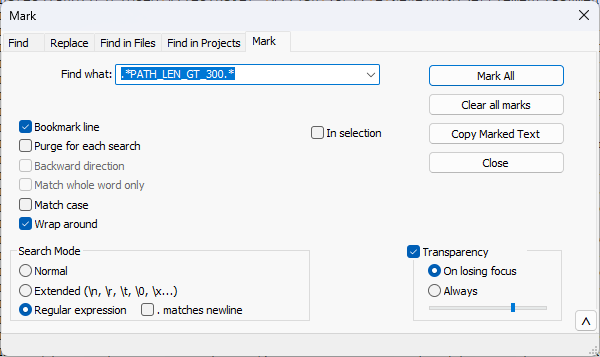
Once the lines are marked, we “Remove Non-Bookmarked Lines”, this process can take a minute or so.
I could further match ~$ and remove those lines, but it would need escaping and it’s small enough to open in Excel so it’s easy enough to just Filter on the error column and then sort the filename column alphabetically and check the start and end of the file to confirm that those errors are all just word temp files.
In my case, there were no SharePoint naming issues aside from the temp word docs and some desktop.ini files as well.
For path length, yes, we had some that needed correcting. 88 lines in total, of course some are all in one very long folder name, so it ended up being about 5-10 that needed some correction.
For fun, I wanted to see what the path length was according to SharePoint migration, I did a new column and selected the path which was in Column B
len(B1)-2525 was how many characters in the UNC and share portion of the path also excluding the “General” share name.

Yep, they’re a bit long, but nothing too crazy, the file system probably stopped them from making them any longer than this. When we configure OneDrive Sync we make sure to set the path for OneDrive to C:\OD because C:\Users\username\OneDrive can get excessive depending on the username.
When this user logs in, he’s not going to sync many of those OneDrive folders. I might do a post about my thoughts on company usernames, I prefer employee numbers for usernames, it’s an unpopular opinion though.
We also change the org name to an acronym, so if this was “Law Offices of Troy McClure” we change it to LOTM, there might be a better way to force the Teams-based SharePoint folders to utilize a different structure, but it does the trick.
